
반도체 - ON 디바이스 AI로 테크 붐 ON (DS투자증권 : 이수림)
AI 모멘텀을 지속시킬 애플의 귀환
애플은 B2C AI의 시장을 열어 AI 수익화에 대한 시장의 우려를 잠재울 것
1) 최근 시장은 비즈니스 모델 부재로 인한 AI 수익성 확보 어려움에 대한 우려를 지속 제기했으나, 아직 생성형 AI가 발전 단계에 있다고 판단하며 버블 우려는 시기상조임.
2) CSP 업체들이 승자독식 구조의 B2B AI 시장을 선점하기 위한 투자를 지속해왔기 때문에 소비자들이 비용을 지불할 만한 서비스가 없었던 것은 사실임.
3) 애플의 AI 시장 진입과 함께 하반기 B2C AI가 제대로 시작되고 2025년 본격화를 전망함.
4) 9/10 애플 아이폰 16 공개, 애플 인텔리전스는 2024년 10월 출시가 전망되며 2025년 상반기까지 순차적인 기능 공개가 이뤄질 것임.
5) AI 스마트폰과 PC 보급과 함께 1~2년 내 유의미한 소비자용 AI 킬러앱 등장, 새로운 응용처(XR, 자율주행)까지 이어지는 그림을 기대함.
애플의 경쟁력 (1) 자체 칩 기반 추론 AI 경쟁력 강화
1) 애플은 자사 제품에 탑재되는 모든 칩을 자체 설계하면서 애플 생태계의 일관성을 강화하고 모든 기기에서 AI 기능이 통합적으로 작동 가능하게 함.
2) M시리즈 칩은 ‘뉴럴 엔진’이라는 전용 AI 프로세서를 내장하고 있어 기기 내에서 실시간으로 AI 추론 작업을 효율적으로 수행 가능함.
3) NPU가 CPU/GPU와 함께 메모리를 공유하기 때문에 데이터를 따로 재가공하지 않아도 즉각적으로 학습이 가능함.
4) M2 울트라 칩은 뉴럴 엔진이 초당 31조 6천억번의 연산을 수행하며, 대형 트랜스포머 모델을 학습시킬 수 있다고 언급함.
5) 자체 칩셋을 활용해 기기 자체에서 머신러닝을 학습하고 활용할 수 있는 생태계까지 기대 가능함.
6) 다른 빅테크 기업들 역시 AI 작업에 최적화된 아키텍처 설계와 비용 효율성, 데이터 보안 등의 이유로 자체 칩 설계 노력을 지속 중임.

애플의 경쟁력 (2) 엣지 디바이스 생태계 기반 AI 수익화 용이
1) 온디바이스 AI는 AI 모델 B2C 확산의 핵심이며, 스마트폰과 PC는 소비자 접근 측면에서 훌륭한 매개체임.
2) 애플은 스마트폰과 PC 두 영역 모두에서 강력한 경쟁력을 가지고 있는 기업임.
3) 또한 아이폰, 아이패드, Mac, 애플워치 등 모든 기기가 하나로 연결되는 생태계를 이미 구축함.
4) 애플의 ADI는 2Q24 기준 22억명을 상회했으며, 높은 고객 침투율 기반 AI 소프트웨어를 사용자에게 자연스럽게 공급할 수 있을 것으로 전망함.

애플의 경쟁력 (3) 플랫폼에서 나오는 절대적인 힘
1) 그간 자사만의 운영체제인 iOS를 통해서 연결됐던 생태계에 애플 인텔리전스가 구독 모델의 형태로 더해지고 향후 Vision Pro까지 연결될 전망임.
2) 하드웨어 판매를 촉진시키는 동시에 해당 기능을 기반으로 하는 서비스 구독을 유도할 수 있음.
3) 개인화된 AI를 통해 애플 플랫폼 내 이용자들의 락인(Lock-in) 효과는 더욱 강화될 것임.
4) 뿐만 아니라 소프트웨어 기업들이 애플 플랫폼에서 사용자 기반을 늘리고 생성형 AI 유료 서비스를 판매해 수익화 시점을 앞당길 수 있을 것이라는 전망도 등장함.
5) 오픈 AI와의 협업 발표 이후 소프트웨어 기업들, 구글과 앤트로픽, 퍼플렉시티 모두 애플 기기에 자사 모델을 탑재하기 위한 협상을 진행 중임.

애플의 AI 투자 현황 및 전망
Apple Intelligence, 온디바이스와 서버를 결합한 AI 전략
1) 애플의 고유한 실리콘 칩셋(A17 Pro, M1 이후 칩)과 뉴럴 엔진을 활용하여 디바이스 자체에서 AI 처리를 수행함.
2) AFM(Apple Foundation Model) 기반 훈련이 이뤄졌으며 약 30억개의 매개변수를 가진 모델이 기기에서 직접 실행됨.
3) 온디바이스 처리가 불가능한 크기의 작업일 경우 애플 데이터센터 내 자체 비공개 서버를 활용하여 연산함.
4) 온디바이스 AI와 클라우드 AI를 결합하면서 기존의 강력한 보안성을 유지, 사용자 데이터는 외부 서버로 전송하지 않고 기기 내에서 안전하게 처리함.
5) 현재는 비용 효율성과 빠른 출시를 위해 Siri에 ChatGPT를 접목하는 방식을 채택했으나 향후 자체 언어모델(AFM) 탑재로 전환 가능성 존재함.
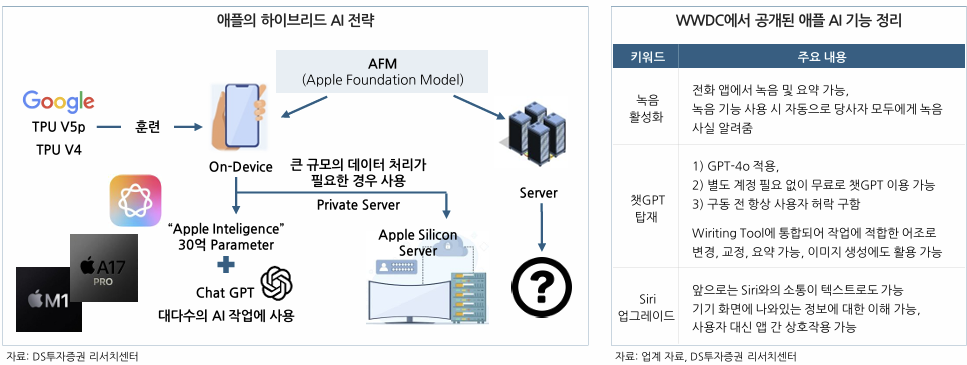
비용/시간 절약 위해 CSP 업체들과 다른 AI 전략 채택
1) 소비자용 IT 기기와 구독 서비스가 주 매출원인 애플은 천문학적인 비용을 투자해 LLM 경쟁에서 선두를 차지할 이유가 없음.
2) 주요 CSP 업체들의 AI 목표가 클라우드 서비스 경쟁력을 높이는 것이라면 애플의 AI 목표는 사용자 경험 향상을 통한 기존 매출 증대임.
3) 비용 효율성과 신속성 위해 인프라 구축은 외주화 + 온디바이스 AI 기술 등에만 집중함.
4) 현재 애플은 구글 클라우드와 TPU를 이용해 애플 인텔리전스와 AFM(Apple Foundation Model)의 학습과 기능 개선을 지속 중임.
5) AI 시장에 경쟁사들 대비 진입이 늦었기 때문에 비용 효율성과 신속성을 높이기 위해 인프라 구축을 외주화함.
6) 다만 M2 울트라 칩을 활용하여 자체 클라우드 인프라 강화하고 있어 장기적으로는 자체 AI 데이터센터를 구축하는 방향으로 나아갈 가능성이 높음.

LLM 개발 위해서는 막대한 비용 필요
1) LLM을 개발하기 위해선 AI 서버를 유지하는데 들어가는 천문학적 비용과 함께 엄청난 분량의 데이터를 수집해야 함.
2) 오픈AI의 GPT-3는 훈련비용 1천만 달러, 하루 운영비 70만 달러를 요구하는 것으로 알려짐.
3) 학습 시간과 전력소비까지 고려한다면 매개변수 증가에 따라 기하급수적으로 데이터 비용이 증가함.
4) GPT-3는 매개변수 1,750억개 모델 학습에 약 9백만 달러 소요 → GPT-4는 매개변수 1조개 학습에 약 3억 달러 이상 소요(30배 증가)됨.
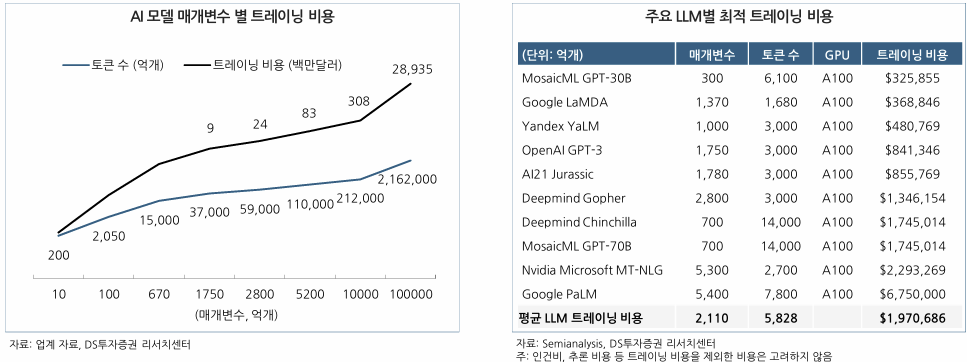
온디바이스에 최적화된 sLM 선택
1) 대규모 LLM보다 효율적이고 온디바이스에서 작동할 수 있는 모델에 더 중점 → sLM(Small Language Model) 개발임.
2) 상대적으로 적은 매개변수를 기반으로 하는 sLM은 LLM 대비 적은 컴퓨팅 파워와 인터넷 연결 없이도 구현 가능함.
3) 동일 토큰 수 기준 LLM은 매개변수 2천억개 훈련에 197만 달러의 비용이 투입되는 반면 sLM은 2백억개 훈련에 13만 달러가 투입됨.

온디바이스 AI를 위한 애플 실리콘 로드맵
애플 인텔리전스는 왜 iPhone15 Pro 이상에서만 지원될까?
1) 애플 인텔리전스는 NPU 속도가 17TOPS인 A16칩(아이폰 15 탑재)은 지원하지 않지만, 11TOPS인 M1칩은 지원함.
2) A16칩의 DRAM 탑재량은 최대 6GB인 반면 AI가 지원되는 A17 Pro는 8GB, M1은 8~16GB의 DRAM 탑재가 가능하기 때문임.
3) 애플 인텔리전스는 현재 30억개의 파라미터로 실행되며, 평균 3.5 Bit 양자화 모델 기준 1.6GB 수준의 RAM을 요구할 것으로 추정 가능함.
4) 향후 파라미터 수가 증가함에 따라 DRAM 탑재량은 더욱 증가할 것으로 전망됨.

AI는 DRAM에 항상 로딩되어 있어 용량을 잡아먹기 때문
1) 메모리 사용량을 최대로 줄인 4 Bit 양자화 기준으로 100억개 파라미터 모델을 실행하려면 약 5GB의 DRAM이 추가로 필요할 것으로 추정됨.
2) 실제로 구글 픽셀9 프로에 탑재된 AI 모델 ‘Gemini 나노’는 사용 여부와 관계없이 3GB RAM 차지함.
3) 구글 픽셀9 프로의 RAM 용량은 16GB, 앱 구동에 사용할 수 있는 실제 RAM 용량은 13GB가 되는 것임.
4) 마이크로소프트 역시 AI PC인 코파일럿+PC 구동 조건으로 최소 16GB RAM을 요구함.

3D 패키징 구조는 메모리 최적화를 위한 효과적인 방안
1) 3D 패키징은 메모리 용량을 늘리면서도 전반적인 시스템 성능을 향상시키고, 더 작은 폼팩터 내에서 더 많은 기능을 구현할 수 있게 함.
2) 동일한 면적 내에서 더 많은 회로와 메모리를 통합할 수 있기 때문에, 칩 크기를 크게 늘리지 않으면서도 메모리 용량을 증가시킬 수 있음.
3) 2.5D 패키징 대비해서도 I/O 핀 개수를 더 늘릴 수 있어 메모리 대역폭과 처리 성능을 극대화할 수 있음.
4) 또한, 메모리와 프로세서를 포함한 칩 간 데이터 전송 거리가 짧아져 데이터 전송에 필요한 전력이 감소함.

애플은 차세대 M5 칩에 TSMC의 3D 패키징 기술 SoIC-X를 적용할 계획
1) 애플은 2025년 말~2026년 초 NPU 성능을 더욱 강화한 M5 칩을 출시하고 Mac과 AI 서버에 사용할 계획으로 알려짐.
2) M5는 현재 TSMC의 SoIC-X 기술을 적용해 시험 생산 중으로 알려져 있으며 N2(2나노) 공정 기술을 사용할 것으로 추정됨.
3) SoIC는 서로 다른 크기, 기능, 공정 노드를 가진 칩들을 쌓아 인터커넥트로 연결하는 TSMC의 3D 패키징 기술임.
4) 기존 SoC(System on Chip) 방식을 넘어서 SoIC(System on Integrated Chip)를 채택한다면 전력 효율성과 메모리 접근 속도 때문이라는 판단임.
5) 대만 Zhunan AP6 조립 및 테스트 시설에서 생산 중이며 Chiayi에 신규 증설 계획을 보유 중임(CAPA 23년 2K/월 → 24년 4K/월 → 27년 10K/월).

SoIC를 통해 전력 소모를 최소화하고 메모리 접근 속도를 높일 수 있을 것
1) SoIC는 서로 다른 칩을 수직으로 쌓아 데이터 전송 경로가 매우 짧아지며, 3D 칩렛 구조인 SoIC는 2D 평면 구조/2.5D 칩렛보다 더 많은 메모리를 작은 면적에 탑재하며, 칩 간 초고밀도 연결이 가능함.
2) DRAM을 로직 다이 위로 쌓아 집적도는 높이면서 칩 간 데이터 전송 거리를 줄여 전력 소모를 최소화하고 데이터 접근 속도를 높일 수 있음.
3) 현재 9μm 까지 매우 미세한 본딩 피치를 지원(2.5D 대비 1/4 수준)하며 2027년까지 3μm 수준 달성이 목표임.
4) SoIC는 CoWoS나 InFO 등의 백엔드 패키징 기술과 조합하여 사용함.

AMD 3D V-Cache로 보는 로직+메모리 적층 효과
1) SoIC 기술을 가장 처음 도입한 것은 AMD의 3D V-Cache 기술을 적용한 라이젠 5000 시리즈임.
2) AMD에 따르면 3D V-Cache는 전력 효율성 측면에서 마이크로 범프 연결 대비 비트 당 에너지가 1/3 이하로 감소함.
3) 또한 칩 당 L3 캐시 용량이 3배로 증가하였으며, 두 다이 간 대역폭은 2TB/s까지 증가함.
4) 3D V-Cache는 칩렛 구조의 프로세서에 추가 캐시 메모리(64MB의 7nm SRAM 캐시)를 수직 적층하여 CPU의 성능을 크게 향상시킴.
5) 이후 AMD MI300 시리즈 생산에 SoIC-X가 적용되었으며 Apple 역시 SoIC-X 시험 생산 중으로 NVIDIA와 Broadcom도 이 기술 도입을 위해 협력 중임.
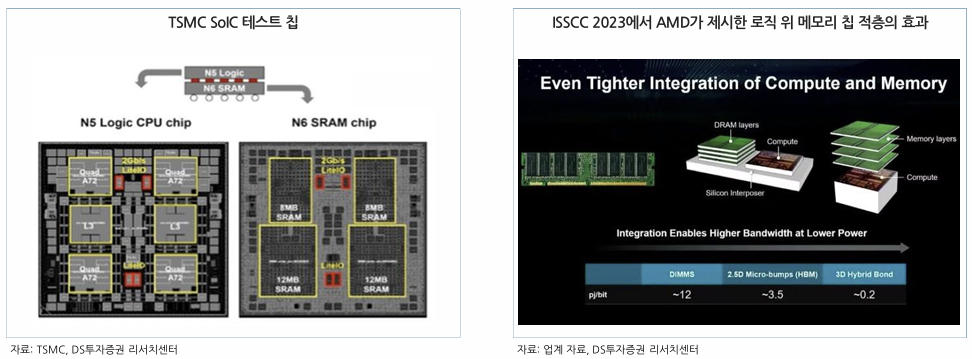
다이 분리로 더욱 효율적인 메모리 사용 가능
1) SoIC-X는 CPU, GPU, 뉴럴 엔진, 메모리 등이 별개의 타일로 구성된 모듈형 설계를 사용함.
2) SoIC 기술에서는 CPU와 GPU, 서로 다른 프로세서가 각각의 전용 메모리 풀을 가질 수 있다는 장점도 존재함.
3) 예를 들어, CPU 위에 적층된 메모리와 GPU 위에 적층된 메모리는 각기 다른 메모리 풀로 작동함.
4) CPU와 GPU가 각각의 전용 메모리 풀을 사용할 경우, 두 프로세서가 독립적으로 메모리 대역폭을 사용하여 병목 현상을 줄이고 더 높은 성능을 발휘할 수 있을 것임.
5) SoIC는 이처럼 유연한 메모리 관리와 프로세서 통합이 가능하다는 장점임.

향후 플래시 메모리가 대안이 될 가능성도 제시
1) 애플은 2023년 12월 ‘LLM in a flash’ 논문에서 AI 모델의 매개변수를 플래시 메모리에 저장하고, 필요할 때만 DRAM으로 로드하는 방법을 제안함.
2) DRAM 용량 업그레이드를 최소화하면서도 온디바이스 AI 모델 성능을 극대화하기 위한 연구임.
3) 플래시 메모리는 저장 가능한 데이터의 양은 많지만 대역폭이 DRAM/CPU/GPU의 캐시 대비 낮다는 문제가 있음.
4) 이를 위해 ‘윈도잉’과 ‘행-열 묶음’ 두 가지 기술을 통해 데이터 전송을 최소화하고 플래시 메모리에서의 읽기 과정을 최적화함.
5) 연구 결과 같은 DRAM 용량으로 최대 2배 사이즈의 모델을 실행하였고 CPU에서는 4~5배, GPU에서는 20~25배의 추론 속도 향상을 확인함.
LLW DRAM에 대한 논의도 지속 중
1) LPDDR 모듈로는 원하는 만큼의 AI 연산 속도를 구현할 수 없고, 디바이스에 HBM을 탑재하자니 전력 소비, 발열, 비용 등 문제 발생함.
2) 이에 LPDDR 대비 I/O 수를 늘리고 병목 현상 해결을 위해 데이터 지연성(Latency)은 절반 수준으로 줄인 LLW DRAM 개념이 등장함.
3) 3D 패키징 기술을 사용하여 LLW 모듈과 메모리, 프로세서 등을 효율적으로 통합함.
4) 애플 비전 프로에는 I/O 개수 512개의 SK하이닉스 LLW DRAM이 연산 칩인 R1 바로 옆에 탑재됨.
5) 기존 LPDDR5 대비 I/O 개수는 8배, 대역폭은 2.5배(128GB/s) 증가했으며 전력효율 70% 향상됨.

'리포트 > 반도체' 카테고리의 다른 글
| 반도체 산업 리포트 : 잠시 눈높이를 조정하는 시간 (5) | 2024.08.30 |
|---|---|
| 2025년, 메모리반도체 Capex 재개 & 쿼츠 시장내 입지 확대 : 원익QnC(074600) - 목표주가 50,000(-) (6) | 2024.08.15 |
| 실적으로 보여주다 : 원익QnC(074600) - 목표주가 48,000(-) (0) | 2024.08.15 |
| 다변화 노력에 대한 결실이 가까워지고 있음 : 대덕전자(353200) - 목표주가 29,000(-) (0) | 2024.08.15 |
| 6년 만에 최대 실적 전망 : SK하이닉스(000660) (0) | 2024.08.15 |




댓글